3 Probability and Bayes Theorem
3.1 Introduction
Probability theory is one of the three central mathematical tools in machine learning, along with multivariable calculus and linear algebra. Tools from probability allow us to manage the uncertainty inherent in data collected from real-world experiments, and to measure the reliability of predictions that we make from that data. In these notes, we will review some of the basic terminology of probability and introduce Bayesian inference as a technique in machine learning problems.
This is a superficial introduction to ideas from probability. For a thorough treatment, see this open-source introduction to probability. For a more applied emphasis, I recommend the excellent online course Probabilistic Systems Analysis and Applied Probability and its associated textbook [1].
3.2 Probability Basics
The theory of probability begins with a set \(X\) of possible events or outcomes, together with a “probability” function \(P\) on certain subsets of \(X\) that measures “how likely” that combination of events is to occur.
The set \(X\) can be discrete or continuous. For example, when flipping a coin, our set of possible events would be the discrete set \(\{H,T\}\) corresponding to the outcomes of flipping heads or tails. When measuring the temperature using a thermometer, our set of possible outcomes might be the set of real numbers, or perhaps an interval in \(\mathbb{R}\). The thermometer’s measurement is random because it is affected by, say, electronic noise, and so its reading is the true temperature perturbed by a random amount.
The values of \(P\) are between \(0\), meaning that the event will not happen, and \(1\), meaning that it is certain to occur. As part of our set up, we assume that the probability of some event from \(X\) occurring is \(1\), so that \(P(X)=1\); and the chance of “nothing” happening is zero, so \(P(\emptyset)=0\). And if \(U\subset X\) is some collection, then \(P(U)\) is the chance of an event from \(U\) occurring.
The last ingredient of this picture of probability is additivity. Namely, we assume that if \(U\) and \(V\) are subsets of \(X\) that are disjoint, then \[ P(U\cup V)=P(U)+P(V). \]
Even more generally, we assume that this holds for countably infinite collections of disjoint subsets \(U_1,U_2,\ldots\), where
\[ P(U_1\cup U_2\cup\cdots)=\sum_{i=1}^{\infty} P(U_i) \]
Definition: The combination of a set \(X\) of possible outcomes and a probability function \(P\) on subsets of \(X\) that satisfies \(P(X)=1\), \(0\le P(U)\le 1\) for all \(U\), and is additive on countable disjoint collections of subsets of \(X\) is called a (naive) probability space. \(X\) is called the sample space and the subsets of \(X\) are called events.
Warning: The reason for the term “naive” in the above definition is that, if \(X\) is an uncountable set such as the real numbers \(\mathbb{R}\), then the conditions in the definition are self-contradictory. This is a deep and rather surprising fact. To make a sensible definition of a probability space, one has to restrict the domain of the probability function \(P\) to certain subsets of \(X\). These ideas form the basis of the mathematical subject known as measure theory. In these notes we will work with explicit probability functions and simple subsets such as intervals that avoid these technicalities.
3.2.1 Discrete probability examples
The simplest probability space arises in the analysis of coin flipping. As mentioned earlier, the set \(X\) contains two elements \(\{H,T\}\). The probability function \(P\) is determined by its value \(P(\{H\})=p\), where \(0\le p\le 1\), which is the chance of the coin yielding a “head”. Since \(P(X)=1\), we have \(P(\{T\})=1-p\).
Other examples of discrete probability spaces arise from dice-rolling and playing cards. For example, suppose we roll two six-sided dice. There are \(36\) equally likely outcomes from this experiment. If instead we consider the sum of the two values on the dice, our outcomes range from \(2\) to \(12\) and the probabilities of these outcomes are given by
| sum(s) | probability |
|---|---|
| 2, 12 | 1/36 |
| 3, 11 | 1/18 |
| 4, 10 | 1/12 |
| 5, 9 | 1/9 |
| 6, 8 | 5/36 |
| 7 | 1/6 |
A traditional deck of \(52\) playing cards contains \(4\) aces. Assuming that the chance of drawing any card is the same (and is therefore equal to \(1/52\)), the probability of drawing an ace is \(4/52=1/13\) since \[ P(\{A_{\clubsuit},A_{\spadesuit},A_{\heartsuit},A_{\diamondsuit}\}) = 4P(\{A_{\clubsuit}\})=4/52=1/13 \]
3.2.2 Continuous probability examples
When the set \(X\) is continuous, such as in the temperature measurement, we measure \(P(U)\), where \(U\subset X\), by giving a “probability density function” \(f:X\to [0,\infty)\) and declaring that \[ P(U) = \int_{U}f(x) dx. \] Notice that our function \(f(x)\) has to satisfy the condition \[ P(X)=\int_{X} f(x)dx = 1. \]
For example, in our temperature measurement example, suppose the “true” outside temperature is \(t_0\), and our thermometer gives a reading \(t\). Then a good model for the random error is to assume that the error \(x=t-t_0\) is governed by the density function
\[ f_\sigma(x) = \frac{1}{\sigma\sqrt{2\pi}}e^{-x^2/2\sigma^2} \]
where \(\sigma\) is a parameter. In a continuous situation such as this one, the probability of any single point in \(X\) is zero since \[ P(\{t\})=\int_{t}^{t}f_{\sigma}(x)dx = 0 \]
Still, the shape of the density function does tell you where the values are concentrated – values where the density function is larger are more likely than those where it is smaller.
With this density function, and \(x=t-t_0\), the error in our measurement is given by \[ P(|t-t_0|<\delta)=\int_{-\delta}^{\delta} \frac{1}{\sigma\sqrt{2\pi}}e^{-x^2/2\sigma^2} dx \tag{3.1}\]
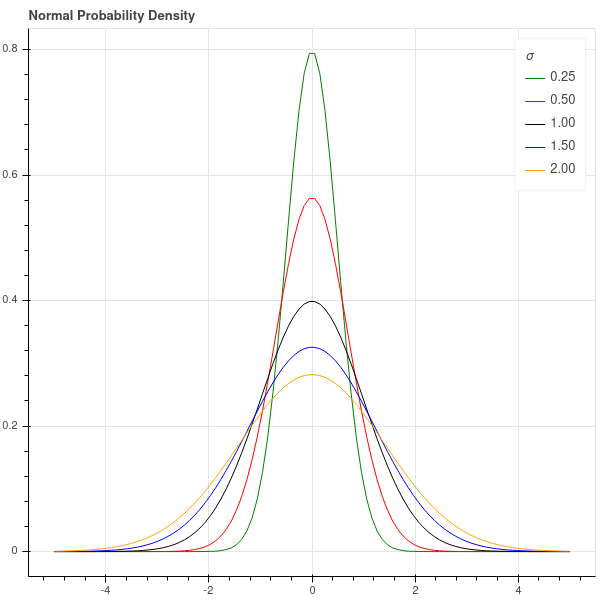
The parameter \(\sigma\) (called the standard deviation) controls how tightly the thermometer’s measurement is clustered around the true value \(t_0\); when \(\sigma\) is large, the measurements are scattered widely, when it is small, they are clustered tightly. See Figure 3.1.
3.3 Conditional Probability and Bayes Theorem
The theory of conditional probability gives a way to study how partial information about an event informs us about the event as a whole. For example, suppose you draw a card at random from a deck. As we’ve seen earlier, the chance that card is an ace is \(1/13\). Now suppose that you somehow learn that the card is definitely not a jack, queen, or king. Since there are 12 cards in the deck that are jacks, kings, or queens, the card you’ve drawn is one of the remaining 40 cards, which includes 4 aces. Thus the chance you are holding an ace is now \(4/40=1/10\).
In terms of notation, if \(A\) is the event “my card is an ace” and \(B\) is the event “my card is not a jack, queen, or king” then we say that the probability of \(A\) given \(B\) is \(1/10\). The notation for this is \[ P(A|B) = 1/10. \]
More generally, if \(A\) and \(B\) are events in a sample space \(X\), and \(P(B)>0\), then \[ P(A|B) = \frac{P(A\cap B)}{P(B)}, \] so that \(P(A|B)\) measures the chance that \(A\) occurs among those situations in which \(B\) occurs.
3.3.1 Bayes Theorem
Bayes theorem is a foundational result in probability.
Theorem: Bayes Theorem says \[ P(A|B) = \frac{P(B|A)P(A)}{P(B)}. \]
If we use the definition of conditional probability given above, this is straightforward: \[ \frac{P(B|A)P(A)}{P(B)} = \frac{P(A\cap B)}{P(B)} = P(A|B). \]
3.3.2 An example
To illustrate conditional probability, let’s consider what happens when we administer the PCR test for COVID-19 to an individual drawn from the population at large. There are two possible test results (positive and negative) and two possible true states (infected and not infected). Suppose I go to the doctor and get a COVID test which comes back positive. What is the probability that I actually have COVID?
Let’s let \(S\) and \(W\) stand for infected (sick) and not infected (well) respectively, and let \(+/-\) stand for test results positive or negative respectively. Note that there are four possible outcomes of our experiment:
- test positive and infected (S+) – this is a true positive.
- test positive and not infected (W+) – this is a false positive.
- test negative and infected (S-) – this is a false negative.
- test negative and not infected (W-) – this is a true negative.
This ICD10 report claimsthat the chance of a false positive – that is, the percentage of samples from well people that incorrectly yields a positive result – is about one-half of one percent, or 5 in 1000.
(Disclaimer: these numbers are unverified and are used for illustration purposes only.)
In other words, \[ P(+|W) = P(W+)/P(W) = 5/1000=1/200 \]
On the other hand, the same source tells us that chance of a false negative is 1 in 4, so \[ P(-|S) = P(S-)/P(S) = .25. \] Since every test is either positive or negative, \(P(S-)+P(S+)=P(S)\) and so \[ P(+|S) = .75. \]
Suppose furthermore that the overall incidence of COVID-19 in the population is \(p\). In other words, \(P(S)=p\) so \(P(W)=1-p\). Then \[P(S+)=P(S)P(+|S)=.75p\] and \[ P(W+)=P(W)P(+|W)=.005(1-p). \] Putting these together we get \(P(+)=.005+.745p\)
We are interested in \(P(S|+)\) – the chance that I’m sick, given that my test result was positive. By Bayes Theorem, \[ P(S|+)=\frac{P(+|S)P(S)}{P(+)}=.75p/(.005+.745p)=\frac{750p}{5+745p}. \]
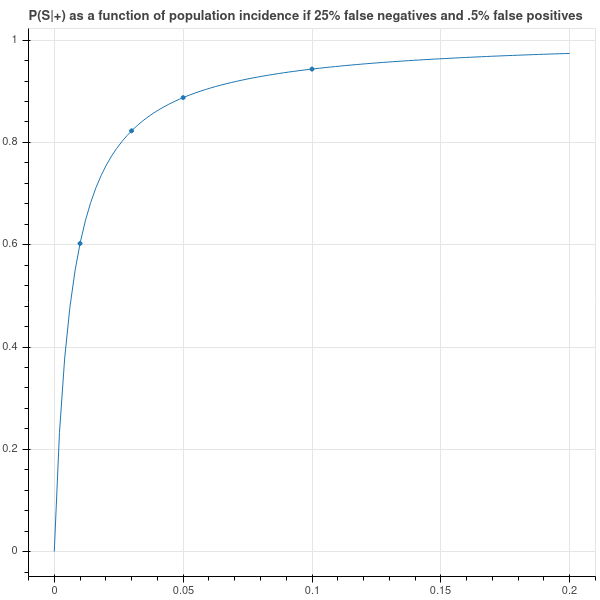
As Figure 3.2 shows, if the population incidence is low then a positive test is far from conclusive. Indeed, if the overall incidence of COVID is one percent, then a positive test result only implies a 60 percent chance that I am in fact infected.
Just to fill out the picture, we have \[ P(-) = P(S-)+P(W-)=(P(S)-P(S+))+(P(W)-P(W+)) \] which yields \[ P(-)=1-.005+.005p-.75p = .995-.745p. \] Using Bayes Theorem, we obtain \[ P(S|-) = \frac{P(-|S)P(S)}{P(-)} = .25p/(.995-.745p) =\frac{250p}{995-745p}. \] In this case, even though the false negative rate is pretty high (25 percent) overall, if the population incidence is one percent, then the probability that you’re sick given a negative result is only about \(.25\) percent. So negative results are very likely correct.
3.4 Independence
Independence is one of the fundamental concepts in probability theory. Conceptually, two events are independent if the occurrence of one has does not influence the likelihood of the occurrence of the other. For example, successive flips of a coin are independent events, since the result of the second flip doesn’t have anything to do with the result of the first. On the other hand, whether or not it rains today and tomorrow are not independent events, since the weather tomorrow depends (in a complicated way) on the weather today.
We can formalize this idea of independence using the following definition.
Definition: Let \(X\) be a sample space and let \(A\) and \(B\) be two events. Then \(A\) and \(B\) are independent if \(P(A\cap B)=P(A)P(B)\). Equivalently, \(A\) and \(B\) are independent if \(P(A|B)=P(A)\) and \(P(B|A)=P(B)\).
3.4.1 Examples
3.4.1.1 Coin Flipping
Suppose our coin has a probability of heads given by a real number \(p\) between \(0\) and \(1\), and we flip our coin \(N\) times. What is the chance of gettting \(k\) heads, where \(0\le k\le N\)? Any particular sequence of heads and tails containing \(k\) heads and \(N-k\) tails has probability \[ P(\hbox{a particular sequence of $k$ heads among $N$ flips}) = p^{k}(1-p)^{N-k}. \] In addition, there are \(\binom{N}{k}\) sequences of heads and tails containing \(k\) heads. Thus the probability \(P(k,N)\) of \(k\) heads among \(N\) flips is \[ P(k,N) = \binom{N}{k}p^{k}(1-p)^{N-k}. \tag{3.2}\]
Notice that the binomial theorem gives us \(\sum_{k=0}^{N} P(k,N) =1\) which is a reassuring check on our work.
The probability distribution on the set \(X=\{0,1,\ldots,N\}\) given by \(P(k,N)\) is called the binomial distribution with parameters \(N\) and \(p\).
3.4.1.2 A simple ‘mixture’
Now let’s look at an example of events that are not independent. Suppose that we have two coins, with probabilities of heads \(p_1\) and \(p_2\) respectively; and assume these probabilities are different. We play the a game in which we first choose one of the two coins (with equal chance) and then flip it twice. Is the result of the second flip independent of the first? In other words, is \(P(HH)=P(H)^2\)?
This type of situation is called a ‘mixture distribution’ because the probability of a head is a “mixture” of the probability coming from the two different coins.
The chance that the first flip is a head is \((p_1+p_2)/2\) because it’s the chance of picking the first coin, and then getting a head, plus the chance of picking the second, and then getting a head. The chance of getting two heads in a row is \((p_1^2+p_2^2)/2\) because it’s the chance, having picked the first coin, of getting two heads, plus the chance, having picked the second, of getting two heads.
Since \[ \frac{p_1^2+p_2^2}{2}\not=\left(\frac{p_1+p_2}{2}\right)^2 \] we see these events are not independent.
In terms of conditional probabilities, the chance that the second flip is a head, given that the first flip is, is computed as: \[ P(HH|H) = \frac{p_1^2+p_2^2}{p_1+p_2}. \] From the Cauchy-Schwartz inequality one can show that \[ \frac{p_1^2+p_2^2}{p_1+p_2}>\frac{p_1+p_2}{2}. \]
Why should this be? Why should the chance of getting a head on the second flip go up given that the first flip was a head? One way to think of this is that the first coin flip contains a little bit of information about which coin we chose. If, for example \(p_1>p_2\), and our first flip is heads, then it’s just a bit more likely that we chose the first coin. As a result, the chance of getting another head is just a bit more likely than if we didn’t have that information. We can make this precise by considering the conditional probability \(P(p=p_1|H)\) that we’ve chosen the first coin given that we flipped a head. From Bayes’ theorem:
\[ P(p=p_1|H) = \frac{P(H|p=p_1)P(p=p_1)}{P(H)}=\frac{p_1}{p_1+p_2}=\frac{1}{1+(p_2/p_1)}>\frac{1}{2} \] since \((1+(p_2/p_1))<2\).
Exercise: Push this argument a bit further. Let \(p_1=\max(p_1,p_2)\) Let \(P_N\) be the conditional probability of getting heads assuming that the first \(N\) flips were heads. Show that \(P_N\to p_1\) as \(N\to\infty\). All those heads piling up make it more and more likely that you’re flipping the first coin and so the chance of getting heads approaches \(p_1\).
3.4.1.3 An example with a continuous distribution
Suppose that we return to our example of a thermometer which measures the ambient temperature with an error that is distributed according to the normal distribution, as in Equation 3.1. Suppose that we make 10 independent measurements \(t_1,\ldots, t_{10}\) of the true temperature \(t_0\). What can we say about the distribution of these measurements?
In this case, independence means that \[ P=P(|t_1-t_0|<\delta,|t_2-t_0|<\delta,\ldots) = P(|t_1-t_0|<\delta)P(|t_2-t_0|<\delta)\cdots P(|t_{10}-t_{0}|<\delta) \] and therefore \[ P = \left(\frac{1}{\sigma\sqrt{2\pi}}\right)^{10}\int_{-\delta}^{\delta}\cdots\int_{-\delta}^{\delta} e^{-(\sum_{i=1}^{10} x_i^2)/2\sigma^2} dx_1\cdots dx_{10} \]
One way to look at this type of multivariate distribution is that the vector \(\mathbf{e}\) of errors \((|t_1-t_0|,\ldots,|t_{10}-t_0|)\) is distributed according to a multivariate gaussian distribution: \[ P(\mathbf{e}\in U) =\left(\frac{1}{\sigma\sqrt{2\pi}}\right)^{10}\int_{U} e^{-\|x\|^2/2\sigma^2} d\mathbf{x} \tag{3.3}\]
where \(x\) is the vector of differences \(t_{i}-t_{0}\) and \(U\) is a region in \(\mathbf{R}^{10}\).
In particular, the magnitude \(\|x\|\)of the error vector \(x\) is normally distributed.
3.5 Random Variables, Mean, and Variance
Typically, when we are studying a random process, we aren’t necessarily accessing the underlying events, but rather we are making measurements that provide us with some information about the underlying events. For example, suppose our sample space \(X\) is the set of throws of a pair of dice, so \(X\) contains the \(36\) possible combinations that can arise from the throws. What we are actually interested is the sum of the values of the two dice – that’s our “measurement” of this system. This rather vague notion of a measurement of a random system is captured by the very general idea of a random variable.
Definition: Let \(X\) be a sample space with probability function \(P\). A random variable on \(X\) is a function \(f:X\to \mathbb{R}\).
Given a random variable \(f\), we can use the probability measure to decide how likely \(f\) is to take a particular value, or values in a particular set by the formula \[ P(f(x)\in U) = P(f^{-1}(U)) \]
In the dice rolling example, the random variable \(S\) that assigns their sum to the pair of values obtained on two dice is a random variable. Those values lie between \(2\) and \(12\) and we have \[ P(S=k) = P(S^{-1}(\{k\}))=P(\{(x,y): x+y=k\}) \] where \((x,y)\) runs through \(\{1,2,\ldots,6\}^{2}\) representing the two values and \(P((x,y))=1/36\) since all throws are equally likely.
Let’s look at a few more examples, starting with what is probably the most fundamental of all.
Definition: Let \(X\) be a sample space with two elements, say \(H\) and \(T\), and suppose that \(P(H)=p\) for some \(0\le p\le 1\). Then the random variable that satisfies \(f(H)=1\) and \(f(T)=0\) is called a Bernoulli random variable with parameter \(p\).
In other words, a Bernoulli random variable gives the value \(1\) when a coin flip is heads, and \(0\) for tails.
Now let’s look at what we earlier called the binomial distribution.
Definition: Let \(X\) be a sample space consisting of strings of \(H\) and \(T\) of length \(N\), with the probability of a particular string \(S\) with \(k\) heads and \(N-k\) tails given by \[ P(S)=p^{k}(1-p)^{N-k} \] for some \(0\le p\le 1\). In other words, \(X\) is the sample space consisting of \(N\) independent flips of a coin with probability of heads given by \(p\).
Let \(f:X\to \mathbb{R}\) be the function which counts the number of \(H\) in the string. We can express \(f\) in terms of Bernoulli random variables; indeed, \[ f=X_1+\ldots+X_N \] where each \(X_i\) is a Bernoulli random variable with parameter \(p\).
Now \[ P(f=k) = \binom{N}{k}p^{k}(1-p)^{N-k} \] since \(f^{-1}(\{k\})\) is the number of elements in the subset of strings of \(H\) and \(T\) of length \(N\) containing exactly \(k\) \(H\)’s. This is our old friend the binomial distribution. So a binomial distribution is the distribution of the sum of \(N\) independent Bernoulli random variables.
For an example with a continuous random variable, suppose our sample space is \(\mathbf{R}^{2}\) and the probability density is the simple multivariate normal \[ P(\mathbf{x}\in U) = \left(\frac{1}{\sqrt{2\pi}}\right)^2\int_{U} e^{-\|\mathbf{x}\|^2/2} d\mathbf{x}. \] Let \(f\) be the random variable \(f(\mathbf{x})=\|\mathbf{x}\|\). The function \(f\) measures the Euclidean distance of a randomly drawn point from the origin. The set \[U=f^{-1}([0,r))\subseteq\mathbf{R}^{2}\] is the circle of radius \(r\) in \(\mathbf{R}^{2}\). The probability that a randomly drawn point lies in this circle is \[ P(f<r) = \left(\frac{1}{\sqrt{2\pi}}\right)^2\int_{U} e^{-\|\mathbf{x}\|^2/2} d\mathbf{x}. \]
We can actually evaluate this integral in closed form by using polar coordinates. We obtain \[ P(f<r) = \left(\frac{1}{\sqrt{2\pi}}\right)^2\int_{\theta=0}^{2\pi}\int_{\rho=0}^{r} e^{-\rho^2/2}\rho d\rho d\theta. \] Since \[ \frac{d}{d\rho}e^{-\rho^2/2}=-\rho e^{-\rho^2/2} \] we have \[\begin{align*} P(f<r)&=-\frac{1}{2\pi}\theta e^{-\rho^2/2}|_{\theta=0}^{2\pi}|_{\rho=0}^{r}\cr &=1-e^{-r^2/2}\cr \end{align*}\]
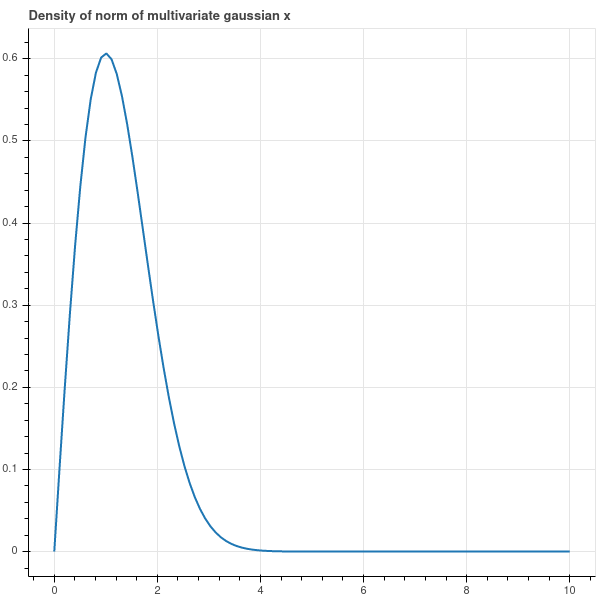
The probability density associated with this random variable is the derivative of \(1-e^{-r^2/2}\) \[ P(f\in [a,b])=\int_{r=a}^{b} re^{-r^2/2} dr \] as you can see by the fundamental theorem of calculus. This density is drawn in Figure 3.3 where you can see that the points are clustered at a distance of \(1\) from the origin.
3.5.1 Independence and Random Variables
We can extend the notion of independence from events to random variables.
Definition: Let \(f\) and \(g\) be two random variables on a sample space \(X\) with probability \(P\). Then \(f\) and \(g\) are independent if, for all intervals \(U\) and \(V\) in \(\mathbb{R}\), the events \(f^{-1}(U)\) and \(g^{-1}(V)\) are independent.
For discrete probability distributions, this means that, for all \(a,b\in\mathbb{R}\), \[ P(f=a\hbox{\ and\ }g=b)=P(f=a)P(g=b). \]
For continous probability distributions given by a density function \(P(x)\), independence can be more complicated to figure out.
3.5.2 Expectation, Mean and Variance
The most fundamental tool in the study of random variables is the concept of “expectation”, which is a fancy version of average. The word “mean” is a synonym for expectation – the mean of a random variable is the same as its expectation or “expected value.”
Definition: Let \(X\) be a sample space with probability measure \(P\). Let \(f:X\to \mathbb{R}\) be a random variable. Then the expectation or expected value \(E[f]\) of \(f\) is \[ E[f] = \int_X f(x)dP. \] More specifically, if \(X\) is discrete, then \[ E[f] = \sum_{x\in X} f(x)P(x) \] while if \(X\) is continuous with probability density function \(p(x)dx\) then \[ E[f] = \int_{X} f(x)p(x)dx. \]
If \(f\) is a Bernoulli random variable with parameter \(p\), then \[ E[f] = 1\cdot p+0\cdot (1-p) = p \]
If \(f\) is a binomial random variable with parameters \(p\) and \(N\), then \[ E[f] = \sum_{i=0}^{N} i\binom{N}{i}p^{i}(1-p)^{N-i} \] One can evaluate this using some combinatorial tricks, but it’s easier to apply this basic fact about expectations.
Proposition: Expectation is linear: \(E[aX+bY]=aE[X]+bE[Y]\) for random variables \(X,Y\) and constants \(a\) and \(b\).
The proof is an easy consequence of the expression of \(E\) as a sum (or integral).
Since a binomial random variable \(Z\) with parameters \(N\) and \(p\) is the sum of \(N\) Bernoulli random variables, its expectation is \[ E[X_1+\cdots+X_N]=Np. \]
A more sophisticated property of expectation is that it is multiplicative when the random variables are independent.
Proposition: Let \(f\) and \(g\) be two independent random variables. Then \(E[fg]=E[f]E[g]\).
Proof: Let’s suppose that the sample space \(X\) is discrete. By definition, \[ E[f]=\sum_{x\in X}f(x)P(x) \] and we can rewrite this as \[ E[f]=\sum_{a\in\mathbf{R}} aP(\{x: f(x)=a\}). \] Let \(Z\subset\mathbb{R}\) be the range of \(f\). Then \[\begin{align*} E[fg]&=\sum_{a\in Z} aP(\{x: fg(x)=a\}) \\ &=\sum_{a\in Z}\sum_{(u,v)\in\genfrac{}{}{0pt}{}{\mathbf{Z}^{2}}{uv=a}}aP(\{x:f(x)=u\hbox{\ and\ }g(x)=v\}) \\ &=\sum_{a\in Z}\sum_{\genfrac{}{}{0pt}{}{\mathbf{Z}^{2}}{uv=a}}uvP(\{x:f(x)=u\})P(\{x:g(x)=v\}) \\ &=\sum_{u\in Z}uP(\{x:f(x)=u\})\sum_{v\in Z}vP(\{x:f(x)=v\}) \\ &=E[f]E[g] \end{align*}\]
3.5.2.1 Variance
The variance of a random variable is a measure of its dispersion around its mean.
Definition: Let \(f\) be a random variable. Then the variance is the expression \[ \sigma^2(f) = E[(f-E[f])^2]=E[f^2]-(E[f])^2 \] The square root of the variance is called the “standard deviation.”
The two formulae for the variance arise from the calculation \[ E[(f-E[f])^2]=E[(f^2-2fE[f]+E[f]^2)]=E[f^2]-2E[f]^2+E[f]^2=E[f^2]-E[f]^2. \]
To compute the variance of the Bernoulli random variable \(f\) with parameter \(p\), we first compute \[ E[f^2]=p(1)^2+(1-p)0^2=p. \] Since \(E[f]=p\), we have \[ \sigma^2(f)=p-p^2=p(1-p). \]
If \(f\) is the binomial random variable with parameters \(N\) and \(p\), we can again use the fact that \(f\) is the sum of \(N\) Bernoulli random variables \(X_1+\cdots+X_n\) and compute
\[\begin{align*} E[(\sum_{i}X_i)^2]-E[\sum_{i} X_{i}]^2 &=E[\sum_{i} X_i^2+\sum_{i,j}X_{i}X_{j}]-N^2p^2\\ &=Np+N(N-1)p^2-N^2p^2 \\ &=Np(1-p) \end{align*}\]
where we have used the fact that the square \(X^2\) of a Bernoulli random variable is equal to \(X\).
For a continuous example, suppose that we consider a sample space \(\mathbb{R}\) with the normal probability density \[ P(x) = \frac{1}{\sigma\sqrt{2\pi}}e^{-x^2/2\sigma^2}dx. \]
The mean of the random variable \(x\) is \[ E[x] =\frac{1}{\sigma\sqrt{2\pi}}\int_{-\infty}^{\infty} xe^{-x^2/2\sigma^2}dx=0 \]
since the function being integrated is odd. The variance is
\[ E[x^2] = \frac{1}{\sigma\sqrt{2\pi}}\int_{-\infty}^{\infty} x^2e^{-x^2/2\sigma^2}dx. \]
The trick to evaluating this integral is to consider the derivative:
\[ \frac{d}{d\sigma}\left[\frac{1}{\sigma\sqrt{2\pi}}\int_{-\infty}^{\infty}e^{-x^2/(2\sigma^2)}dx\right]=0 \]
where the result is zero since the quantity being differentiated is a constant (namely \(1\)). Sorting through the resulting equation leads to the fact that
\[ E[x^2]=\sigma^2 \]
so that the \(\sigma^2\) parameter in the normal distribution really is the variance of the associated random variable.
3.5.2.2 Covariance and the Multivariate Normal Distribution
Given two random variables \(f\) and \(g\), we can measure how much they vary together by looking at their covariance, which is the expected value of the product of their deviations from their means: \[ \hbox{Cov}(f,g) = E[(f-E[f])(g-E[g])]=E[fg]-E[f]E[g]. \]
If \(f\) and \(g\) are independent, then their covariance is zero.
In our discussion of linear regression and principal components, we made use of the “covariance matrix” \(D_{0}\) which was computed from sample data as \(X_{0}^{T}X_{0}/N\) where \(X_{0}\) was the mean-centered data matrix. The entries of this matrix were the covariances of samples from the various random variables corresponding to the columns of \(X\).
The theoretical origin of the covariance matrix arises from the “multivariate normal distribution” which generalizes the one-dimensional normal distribution and the more general distribution of \(n\) independent normal random variables.
A general multivariate gaussian can be constructed from a covariance matrix \(D_{0}\), where \(D_{0}\) is an \(n\times n\), symmetric, positive definite matrix like we considered in the chapter on principal component analysis. In this case, the probability that an \(n\)-dimensional vector \(x\) lies in a set \(U\subset \mathbf{R}^{n}\) is given by the integral
\[ P(x\in U) = \frac{1}{(2\pi)^{n/2}\sqrt{\det(D_{0})}}\int_{U} e^{-x^{T}D_{0}^{-1}x/2} d\mathbf{x}. \]
If a random vector \(x=(x_1,\ldots, x_n)\) has this distribution, then the individual components \(x_{i}\) are normally distributed with variances given by the diagonal entries of \(D_{0}\), and covariances corresponding to the off-diagonal entries. In other words, \(D_{0}\) is the covariance matrix of the components of \(x\).
To see this, imagine that \(x\) has the given distribution. Using the spectral theorem, we can write \(D_{0}=V\Lambda V^{T}\) where \(V\) is an orthogonal matrix and \(\Lambda\) is a diagonal matrix with positive entries \(\lambda_{1},\ldots, \lambda_{n}\).
If \(y=V^{T}x\), which is a rotation of the random vector \(x=Vy\), then the exponential in the probability density function becomes \[ x^{T}D_{0}^{-1}x = y^{T}V^{T}D_{0}^{-1}Vy = y^{T}V^{T}V\Lambda^{-1}V^{T}Vy = y^{T}\Lambda^{-1}y. \]
Since \(\Lambda\) is diagonal, the normalizing constant \(\sqrt{\det(D_{0})}=\sqrt{\prod_{i=1}^{n}\lambda_{i}}\) becomes the square root of the product of the variances \(\lambda_{i}\), and the density function is visibly the product of \(n\) independent normal distributions with variances \(\lambda_{i}\).
In other words, the random vector \(v\), when rotated into the coordinates given by the eigenvectors of \(D_{0}\), becomes a vector \(y\) whose components are independent normal random variables with variances \(\lambda_{i}\).
WOrking backwards, we can find the covariance matrix of the \(x_{i}\). The matrix \(n\times n\) matrix \(xx^{T}\) has entries \(x_{i}x_{j}\), so the expected values of the entries are the variances/covariances of the \(x_{i}\). But \[ E(xx^{T})=E(Vyy^{T}V^{T}) = VE(yy^{T})V^{T} = V\Lambda V^{T}=D_{0}. \]
In other words, the covariance matrix of the components of \(x\) is \(D_{0}\).
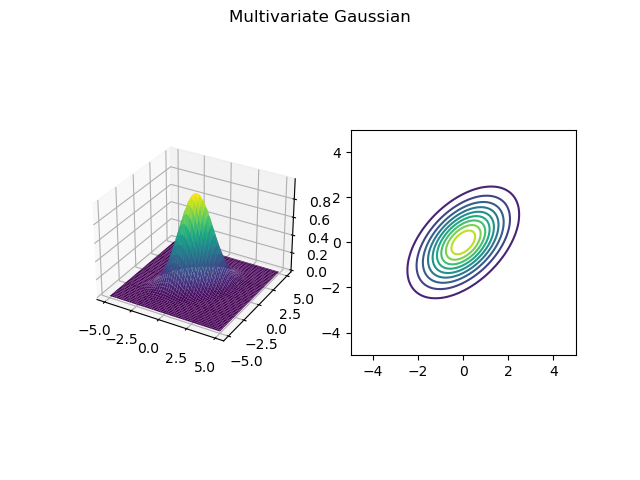
This density function as a “bump” concentrated near the origin in \(\mathbf{R}^{2}\), and its level curves are a family of ellipses centered at the origin. See Figure 3.4 for a plot of this function with \(\sigma=1\).
In this situation we can look at the conditional probability of the first variable given the second, and see that the two variables are not independent. Indeed, if we fix \(x_2\), then the distribution of \(x_1\) depends on our choice of \(x_2\). We could see this by a calculation, or we can just look at the graph: if \(x_2=0\), then the most likely values of \(x_1\) cluster near zero, while if \(x_2=1\), then the most likely values of \(x_1\) cluster somewhere above zero.
3.5.2.3 Application: a tiny bit of portfolio theory
We can see one application of the multivariate gaussian distribution in a very simple model from financial mathematics.
Suppose we look at a collection of \(n\) stocks. We make the very naive assumption that the performance of these stocks is given by (for each stock) an average price per share of \(\mu_{i}\) with variance \(\sigma^2_{i}\) for \(i=1,\ldots, n\). Rule out longer term trends over time and assume that each stock fluctuates around its average price per share according to a normal distribution with mean \(\mu_{i}\) and variance \(\sigma^2_{i}\).
We can think of the individual variances \(\sigma^2_{i}\) as measuring the “risk” associated with each stock. A high variance means the return flucuates a lot around the mean return \(\mu_{i}\).
It would be a mistake, however, to think that the performance of these stocks is independent of each other. For example, the performance of socks of companies in the same industry, tend to be correlated, and all stocks are correlated with the underlying economy. So a reasonable model for the collective performance of these stocks is the return is given by a multivariate gaussian distribution associated with an \(n\times n\) covariance matrix. It’s worth noting that, in finance, the covariance between the performance of two securities is typically called “beta”.
To make this concrete, suppose we are dealing with two securities and their covariance matrix is \[ D = \begin{pmatrix}1.5 & .7 \\ .7 & 1.0\end{pmatrix} \]
If we sample the returns of these stocks (centered at their means, so the distribution of returns is around the origin) we get a plot like this.
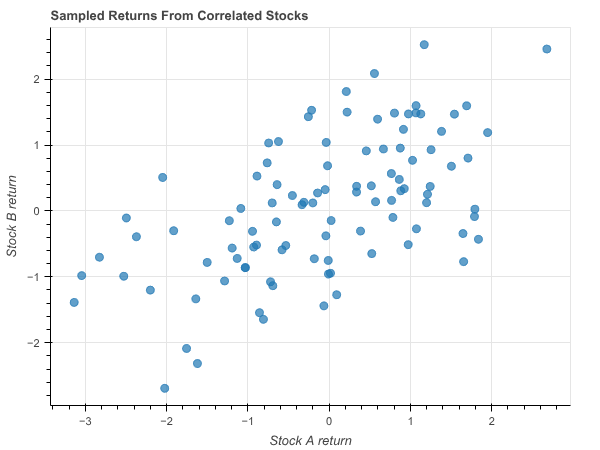
Notice that the stocks perform well or poorly together reflecting the fact that their returns are correlated.
Now suppose we have \(1000\) dollars to invest in these stocks. We can by \(p_{i}\) shares of each stock and we must have
\[ \sum p_{i}\mu_{i} = 1000. \]
The risk associated with this “portfolio” is captured by the variance of this linear combination of the normally distributed stock returns. That, in turn, is yet another example of the variance of a “score” and it is given by \[ \sigma^2 = \left[\begin{matrix} p_1 & \cdots & p_{n}\end{matrix}\right] D_{0} \left[\begin{matrix} p_1 \\ \cdots \\ p_{n}\end{matrix}\right] \] which works out to the quadratic function \[ \sigma^2 = \sum_{i,j} p_{i}p_{j}\sigma_{ij} \] where \(\sigma_{ij}\) is the covariance of stock \(i\) with stock \(j\) (and \(\sigma_{ii}=\sigma^2_{i}\) is the variance of stock \(i\).)
A reasonable goal for us would be to invest our money so as to obtain the same return with the minimum risk. In this setting, that means we want to choose \(p_{i}\) so that \(\sum p_{i}\mu_{i}=1000\) and \(\sigma^2\) is minimized.
This is a constrained optimization problem that we can solve analytically by Lagrange multipliers. If we consider only two dimensions for simplicity, the objective function (the risk) is a quadratic: \[ \sigma^2(p_1,p_2) = \sigma_{1}^2p_1^2+2\sigma_{12}p_{1}p_{2}+\sigma_{2}^2p_{2} \] while the constraint is a line \(p_1\mu_1+p_2\mu_2=1000\).
The Lagrange formulation is \[ L(p_1,p_2,\lambda) = \sigma_{1}^2p_1^2+2\sigma_{12}p_{1}p_{2}+\sigma_{2}^2p_{2}-\lambda(p_1\mu_2+p_2\mu_2-1000) \]
The geometry looks like this graph:
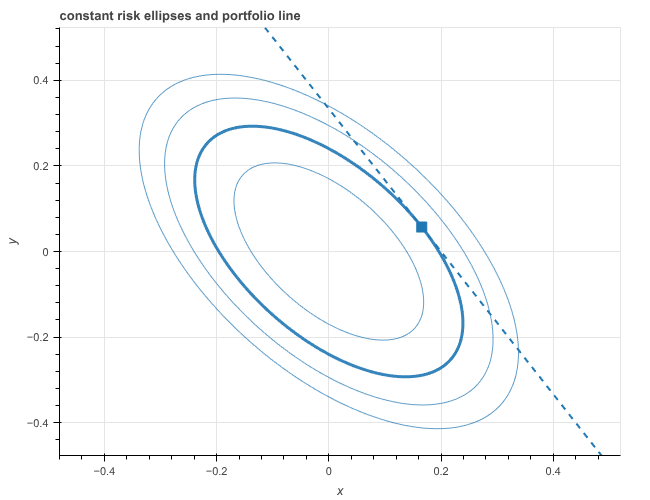
and the point of minimum risk occurs on the “risk ellipse” that is tangent to the “portfolio line.”
The most significant conclusion one obtains from this analysis is that, in general, a diversified portfolio generates the same return at lower risk than a single security. In our graph, the point of tangency occurs at a point where both \(p_1\) and \(p_2\) are nonzero, meaning we have bought a mix of both stocks.
3.6 Models and Likelihood
A statistical model is a mathematical model that accounts for data via a process that incorporates random behavior in a structured way. We have seen several examples of such models in our discussion so far. For example, the Bernoulli process that describes the outcome of a series of coin flips as independent choices of heads or tails with probability \(p\) is a simple statistical model; our more complicated mixture model in which we choose one of two coins at random and then flip that is a more complicated model.
Our description of the variation in temperature measurements as arising from perturbations from the true temperature by a normally distributed amount is another example of a statistical model, this one involving a continuous random variable.
When we apply a mathematical model to understand data, we often have a variety of parameters in the model that we must adjust to get the model to best “fit” the observed data. For example, suppose that we observe the vibrations of a block attached to a spring. We know that the motion is governed by a second order linear differential equation, but the dynamics depend on the mass of the block, the spring constant, and the damping coefficient. By measuring the dynamics of the block over time, we can try to work backwards to figure out these parameters, after which we will be able to predict the block’s motion into the future.
3.6.1 Maximum Likelihood (Discrete Case)
To see this process in a statistical setting, let’s return to the simple example of a coin flip. The only parameter in our model is the probability \(p\) of getting heads on a particular flip. Suppose that we flip the coin \(100\) times and get \(55\) heads and \(45\) tails. What can we say about \(p\)?
We will approach this question via the “likelihood” function for our data. We ask: for a particular value of the parameter \(p\), how likely is this outcome? From Equation 3.2 we have \[ P(55H,45T)=\binom{100}{55}p^{55}(1-p)^{45}. \]
This function is plotted in Figure 3.7. As you can see from that plot, it is extremely unlikely that we would have gotten \(55\) heads if \(p\) was smaller than \(.4\) or greater than \(.7\), while the most likely value of \(p\) occurs at the maximum value of this function, and a little calculus tells us that this point is where \(p=.55\). This most likely value of \(p\) is called the maximum likelihood estimate for the parameter \(p\).
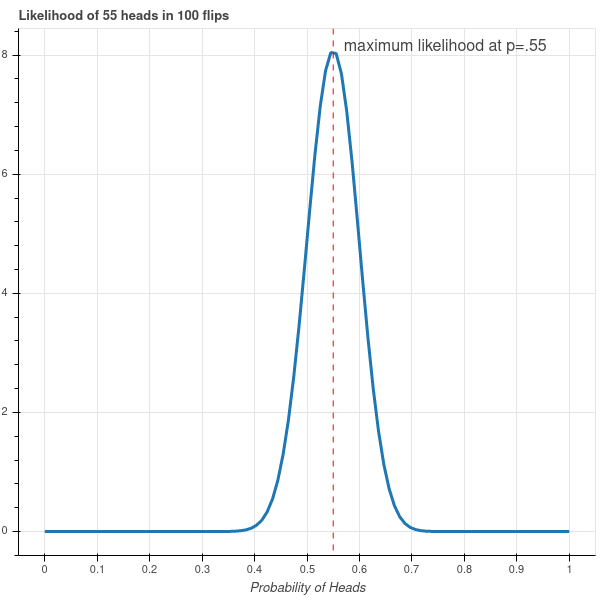
3.6.2 Maximum Likelihood (Continuous Case)
Now let’s look at our temperature measurements where the error is normally distributed with variance parameter \(\sigma^2\). As we have seen earlier, the probability density of errors \(\mathbf{x}=(x_1,\ldots,x_n)\) of \(n\) independent measurements is \[ P(\mathbf{x}) = \left(\frac{1}{\sigma\sqrt{2\pi}}\right)^{n}e^{-\|\mathbf{x}\|^2/(2\sigma^2)}d\mathbf{x}. \] (see Equation 3.3). What should we use as the parameter \(\sigma\)? We can ask which choice of \(\sigma\) makes our data most likely. To calculate this, we think of the probability of a function of \(\sigma\) and use Calculus to find the maximum. It’s easier to do this with the logarithm.
\[ \log P(\mathbf{x})=\frac{-\|\mathbf{x}\|^2}{2\sigma^2}-n\log{\sigma}+C \] where \(C\) is a constant that we’ll ignore. Taking the derivative and setting it to zero, we obtain \[ -\|\mathbf{x}\|^2\sigma^{-3}-n\sigma^{-1}=0 \] which gives the formula \[ \sigma^2=\frac{\|\mathbf{x}\|^2}{n} \]
This should look familiar! The maximum likelihood estimate of the variance is the mean-squared-error.
3.6.3 Linear Regression and likelihood
In our earlier lectures we discussed linear regression at length. Our introduction of ideas from probability give us new insight into this fundamental tool. Consider a statistical model in which certain measured values \(y\) depend linearly on \(x\) up to a normally distributed error: \[ y=mx+b+\epsilon \] where \(\epsilon\) is drawn from the normal distribution with variance \(\sigma^2\).
The classic regression setting has us measuring a collection of \(N\) points \((x_i,y_i)\) and then asking for the “best” \(m\), \(b\), and \(\sigma^2\) to explain these measurements. Using the likelihood perspective, each value \(y_i-mx_i-b\) is an independent draw from the normal distribution with variance \(\sigma^2\), exactly like our temperature measurements in the one variable case.
The likelihood (density) of those draws is therefore \[ P = \left(\frac{1}{\sigma\sqrt{2\pi}}\right)^Ne^{-\sum_{i}(y_i-mx_i-b)^2/(2\sigma^2)}. \] What is the maximum likelihood estimate of the parameters \(m\), \(b\), and \(\sigma^2\)?
To find this we look at the logarithm of \(P\) and take derivatives. \[ \log(P) = -N\log(\sigma) -\frac{1}{2\sigma^2}\sum_{i}(y_i-mx_i-b)^2. \]
As far as \(m\) and \(b\) are concerned, the minimum comes from the derivatives with respect to \(m\) and \(b\) of \[ \sum_{i}(y_i-mx_i-b)^2. \] In other words, the maximum likelihood estimate \(m_*\) and \(b_*\) for \(m\) and \(b\) are exactly the ordinary least squares estimates.
As far as \(\sigma^2\) is concerned, we find just as above that the maximum likelihood estimate \(\sigma^2_*\) is the mean squared error \[ \sigma^2_*=\frac{1}{N}\sum_{i}(y_i-m_*x_i-b_*)^2. \]
The multivariate case of regression proposes a model of the form \[ Y=X\beta+\epsilon \] and a similar calculation again shows that the least squares estimates for \(\beta\) are the maximum likelihood values for this model.